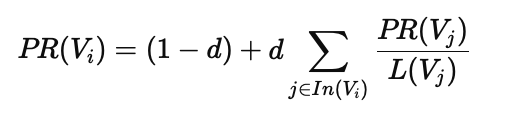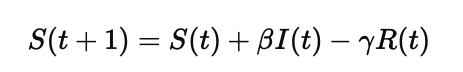在人类语言的复杂系统中,语音是最基础、最直观的层面之一。他是文字的前身。从古典语言学的音位理论,到现代神经网络驱动的语音识别与合成系统,语音学始终贯穿其中,既是语言科学的根基,也是智能技术的前沿。
在深度学习取得显著突破的今天,语音学的角色似乎被边缘化。但语音学并未过时,它只是换了一种方式嵌入我们的模型、算法与认知中。
呼吸、发声与声音建模
人类的发声系统本质上是一种气流驱动的机械装置。我们大多数语言的音流来自于肺部的呼气动作,称为“肺外呼气气流”。气流经过喉头(larynx),激发声带(vocal folds)产生振动,这个过程构成声音的源头。
声带的振动是一个高度周期性的过程,其物理基础可由文丘里效应和伯努利原理解释:气流在通过狭窄的声门时加速,局部气压下降,从而导致声带周期性开合。这一过程构成音的基本来源。
平均而言,成年男性的声带振动频率(F0)约为 100–130Hz,女性则为 200–250Hz。这一生理差异也是我们区分男女声的重要依据之一。
共鸣与调音机制:从原始声波到语言音色
声带产生的声波只是“原始材料”。这些声波在通过声道(vocal tract)时,被不同的腔体结构所修饰,形成我们所感知的各类语音单位。
声带产生的是周期性振动声波,产生有声的音(voiced sound),或者是简单的气流产生的无声的音(voiceless),比如窃窃私语;
共鸣现象使得某些频率成分在声道中被增强,形成共振峰(formants),决定了元音的音色。例如,[i] 与 [a] 虽然同为有声的音,但其 F1 和 F2 的频率显著不同,反映出舌位和开口度的区别。
不同的声道形状(舌位、嘴型、唇圆等),会把这些声音塑形成不同的音素;国际音标(IPA)就是用符号记录这些音素,而不是记录声带发出的“原始材料”。
调音动作则决定辅音与元音的边界特性。通过调整舌头、唇形、软腭等部位的位置与状态,气流在口腔与鼻腔中被不同方式地操控,构成丰富的音素类型。
人体声学器官是一个动态的信号处理系统。声带是脉冲列或者白噪声。舌头,唇形,软腭是可调参数的数字滤波器,从而调制信号频谱。鼻子则是并联滤波器。唇与齿还是开关(门控器)。它们共同作用,构成一个具有时变激励 + 非线性滤波 + 多路径共振 + 动态调控等功能的复杂模拟系统。调音动作就是在修改这些参数。而数字信号处理DSP则用一系列模块化函数来逼近和模拟这种处理过程。
音标并不是对解剖结构的直接描写,而是对“发音结果”(即我们能听出来的语音类别)做出的听觉+生理双重标记。音标反映了:舌头怎么动?嘴巴怎么开?气流怎么流?我们感知到了什么差异?
阉伶歌手的声学奇迹
17-18世纪的欧洲歌剧舞台上,曾有一类令人震撼的歌手——阉伶(Castrati)。他们在童年接受阉割手术,因此保留了童声时期的声带长度与张力,但随着年龄增长,胸廓和共鸣腔发育为成人男性的结构,形成兼具明亮高音与强大共鸣的独特音色。巴洛克歌剧的咏叹调结构复杂、旋律流畅、装饰音繁多,极需高超的技巧与音域控制,正契合阉伶的声乐优势。尤其是Farinelli,据记载其音色如“高音区的雷鸣”,在当时享有极高声誉,不仅技艺非凡,还以一种近乎超自然的方式,唤起贵族女性强烈的情感与生理共鸣,被称为“音乐高潮”的缔造者。
然而,Farinelli的身份也充满悖论:他既拥有雄性躯体的力量感,又因失去性功能而脱离传统性别角色。这种身体与声音之间的错位,使他的舞台形象既迷人又令人困惑,强化了巴洛克歌剧中人性、欲望与牺牲的主题。这一戏剧张力在同名电影《Farinelli》中亦有深刻展现,影片在极致音乐之美之外,也直面了阉伶作为“非完整之人”的情感困境。
为了尽量模拟Farinelli的传奇之声,剧组运用了数字信号处理(DSP)技术,将男高音与女高音的声音融合为一。这种前所未有的音色,虽仍无法真正还原Farinelli的完美,却已是人间难得一听的奇迹,彰显了科技与艺术的融合尝试。
现存唯一一段阉伶录音录于约1900年,演唱者为当时年逾七旬的最后一位阉伶 Alessandro Moreschi,录音条件原始,嗓音也已退化。尽管如此,其在高音区的发声依然声带全开,展现出强烈的穿透力和开放共鸣,极具辨识度。即便现代的女高音或假声男高音能达到类似音高,却难以复现那种音色的饱满与力度。
阉伶歌手的发声特征展示了解剖结构对声学表现的深刻影响,也成为后世研究发声生理与音色关系的重要案例。
声音的物理特性与感知
在语音学中,声音被看作一系列可测量的物理信号。其关键参数包括:
- 频率:反映声波的周期,决定感知音高;
- 振幅:反映声波的能量,决定响度;
- 持续时间:反映语音单位的时间跨度;
- 共振峰:反映声道形状对频率的选择性增强。
声谱图作为语音可视化工具,是现代语音处理中的核心技术之一。它展示了频率与时间的二维分布,并以灰度或色阶反映强度,广泛用于语音识别、合成与说话人识别等任务。
人类感知的 Pitch(音高)并非等同于频率。它是人类对基本频率(F0)的主观感知结果。在 100Hz 到 1000Hz 范围内,音高感知近似线性;而在更高频率上,则呈现出对数式增长趋势。
为了更好地模拟这种感知,语音学中引入了 Mel 音阶:
mel(f) = 1127 × ln(1 + f / 700)
这一转换模型常用于语音识别中的声学特征提取,如 MFCC(Mel Frequency Cepstral Coefficients)。
对数Mel倒谱是将语音信号的频谱信息经过 Mel 频率缩放、对数运算和离散余弦变换(DCT)得到的一组低维特征。它通常编码29个维度的特征向量,是针对人类听觉建立的模型,这些特征有效地保留了人类语音中最能区分音素的信息(尤其是共振峰的分布),而抑制了说话人、语速等冗余因素。是语音识别的基础。
语音学的系统分类框架
在对音素进行分类时,语音学采用三个正交维度:
- 发音部位:如唇音(labial)、齿龈音(alveolar)、软腭音(velar)等;
- 发音方式:如爆破音(stop)、摩擦音(fricative)、鼻音(nasal)、近似音(approximant);
- 发声状态:声带是否振动。
这套系统不仅在语言学研究中使用,也是现代语音合成(TTS)与识别(ASR)系统设计的重要参考依据。
例如,音素的发音方式和部位信息,常被用于辅助建模语音特征,提升系统的自然度和准确率。
韵律与语调
在自然语言交流中,语音并不只是音素的拼接,还包括句子层级的韵律系统(prosody)。Prosody 不是中文的单个字发音所用的调号,而是高于单字的语调韵,描述的是整体的特性。它包括三个关键方面:
- Prominence(显著性):突出重读或语音强度的差异;
- Structure/Boundaries(结构与边界):指话语中自然的分组与停顿;
- Tune(语调曲线):句子的音高走向,如上扬疑问句或下降陈述句。
其中,Tune(语调曲线)尤为关键,它承载了大量句法与语用的信息。
WH-Question Tune
WH疑问句(如who, what, where等)通常采用下降调(falling contour),与陈述句非常相似。这种语调传达出一种“我预期你有答案”的期待感,而不是开放式的疑惑。
Rising Statements 与 Yes-No Questions
另一方面,当陈述句带有高升调(High Rising Statement)时,往往意味着说话人寻求确认或认同。
而标准的是非疑问句(Yes-No Question),则从主要重读(main accent)后开始上升,并在句末保持上升,表现出对肯定或否定回答的期待。
Surprise-Redundancy Tune 与 Contradiction Tune
不同的语境下,语调还会展现出更复杂的变化:
- Surprise-Redundancy Tune:低起点,逐渐升高到句末,传达轻微惊讶或强调多余信息。
- Contradiction Tune:陡然下降开头,之后保持平直,句末再上升,用以强调与先前信息的对立或质疑。
根据 Ladd(1996)的定义,语调是一种超音段(suprasegmental)特征,承载的是句法与语用层级的意义表达。
在韵律层次上,句子的划分也极为重要。
- 单一语调片段(Single Intonation Phrase):
整句话由一个完整的音调流覆盖,常见于简单广泛焦点的陈述句,如:
“Many natural foods are healthy.”
- 多语调分段(Multiple Intonation Phrases):
更长的句子可被划分成多个小片段(phrases),每段带有独立的微调变化,帮助听众分辨信息单元,如:
“I met Mary / and Elena’s mother / at the mall yesterday.”
每个短语的停顿与音调边界清晰地提示了句法结构。
这种划分有时也能帮助消歧义(Phrasing Helps Disambiguate),比如:
- 平铺直叙:“Mary and Elena’s mother mall”,容易理解错。
- 适当分块:“Mary / Elena’s mother / mall”,句子层次清晰,意义明确。
在一个语调片段内部,通常不仅仅有一个重读点。
- 核重音(Nuclear Accent):
指的是最后一个最突出的重音,通常承担着语义焦点,如对比、强调等功能。
例如:“I know SOMETHING interesting is sure to happen.”,其中“SOMETHING”是核重音。
- 其他显著层次(Levels of Prominence):
从强强调(emphatic accent)、普通重音(pitch accent)、无重音(unaccented)、到弱化词(reduced),构成了丰富的语音突出体系。
在TTS系统中,这种多层次的重读建模也成为生成自然、富有表达力语音的关键。
语音合成:TTS
最早期的Text To Speech (TTS)不使用计算机而是机械,有了计算机之后产生程序化拼接发音,机器人味道很重。本世纪初产生了基于深度学习的TTS,首次出现了自然多变的声音。然后这两年产生了端到端的TTS,基本上达到了人类声音效果。
历史TTS:在人类探索声音模拟的历史中,18世纪至20世纪的机械式语音合成器堪称先驱。
1780 — Wolfgang von Kempelen 的发声机由小哨子模拟辅音发音。使用橡胶制成的嘴和鼻子调制元音,发非鼻音时需要用手指堵住鼻孔。无声音(如/p/, /t/)则由辅助风箱通过绳索驱动,制造气流爆破效果。
1939 — Homer Dudley 的 VODER(Voice Operation Demonstrator)
通过复杂的键盘手动控制,模拟不同语音单元。但是操作难度极高,操作员需长时间训练才能产生可理解的语音。演示时常用技巧:提前告诉观众即将听到的内容,显著提高理解率。
1950年代 — Gunnar Fant 的 OVE Synthesizer由瑞典皇家理工学院(KTH)开发,进一步模拟声道动态变化。但是控制参数极为复杂,操作员训练依旧是主要瓶颈。
这段历史清楚展示出一个事实:即使在最早期的TTS探索中,人类也意识到发音机制的复杂性,并不断努力在模型、控制与感知之间寻找平衡。
早期拼接式TTS,把音素录音拼块拼接,听起来像机器人。TTS的恶名就是从那时候开始流传。然后发展出隐马尔可夫过程的HMM TTS利用音素参数建模,构造基准频率,共振峰,终于可以调节语气语调,它的机械感淡了一些,但是语音质量还是很差。
自从2010年前后,基于深度学习的TTS开始流行起来。流行的模型比如早期的Tacotron系列和晚期的FastSpeech系列。深度学习模型不再依靠语音学规则,而是从数据中自动学习韵律、音色、节奏特征。
它们通常把TTS分为两个阶段,第一个阶段是文本分析,第二个阶段是产生声音。第一阶段产生的结果是Mel频谱图。然后再通过它产生声音。这种使用中间表示层的处理方法有一定的好处,在文本处理阶段,可以单独收集文本数据(不需要声音),在音频生成阶段,可以单独收集语音数据(不需要文本对齐太精准)。同时Mel频谱图和人类识别声音的方式有诸多相似之处,易于操纵和处理。
在第一个阶段里,第一步就是把文字清洗成干净的可表达的文字,一串数字,如果是当成日期时间,或者是电话号码,它们以声音的表达方式并不一样,因此需要被明确的标注出来,包括特殊符号之类的。如何把原始混乱的文本,转化成标准化的文本表示。有众多模型可以选择,尤其是NLP语言模型。下面是一个显式中间表示层的例子:
{
"text": "read",
"pronunciation": "ɹiːd",
"pitch": "medium",
"pause_after": "150ms",
"emphasis": "strong"
}
然后单个字符或者两三个字符一起被转变成对应的音素,类似从字母组合产生音标,这一步称作G2P,也有很多的G2P方案可供选择。
同时,系统必须不仅产生正确的音素序列,还要在中间表示层显式或隐式地建模韵律信息——例如重读位置、停顿断句、音高轮廓变化等。否则,生成的语音即便发音准确,也会显得僵硬或不自然。这些音素需要被拼接起来,把基频率F0对齐。
第二个阶段根据标准化文本 + 韵律信息 → 生成语音波形。这个部件称作声码器,Vocoder。尤其是基于生成式对抗网络GAN的vocoders是近年来最佳声码器。例子有MelGAN, Parallel WaveGAN, HiFiGAN等等。其中Mel频谱图,因为声音从时谱转换成频谱,经过了短期快速傅立叶变换,所以相位信息丢失,在产生语音的时候还需要进行相位对齐,好在人类对于相位不是特别敏感。这个阶段有代表性的TTS还有 Tortoise TTS,速度很慢,但是质量极高,性能极稳,用来配音很不错,适合离线高质量语音生成。
端到端模型的出现:mel频谱难以捕捉长期韵律结构,且局部编辑困难。所以,近年来,端到端的TTS开始出现,这些TTS不再显式的训练Mel频谱这种中间表达方式,从连续变量走向离散变量。
2021 年的NAVER发布的VITS是早期端到端模型的代表,它直接把中间层和最终输出同时进行训练,避免了显式中间层。VITS采用了当时最佳技术,比如使用Flow可逆模型,Flow类似扩散模型,但是使用可逆的映射,因此可以把原始信息还原出来。在比较的时候,从文字材料和录音材料中分别识别出潜变量,利用KL散度进行训练,然后生成的语音再通过GAN和原始语音予以比较。其损失函数包括训练损失和GAN的判别损失。因此做到了:在波形并不逐点相同的情况下,感知上比较真实。最终在推理阶段使用HiFI-Gan来产生波形音频。VITS 是第一个真正做到“高质量 + 高效率 + 端到端”的 TTS 模型,它成功融合了 VAE、Flow 和 GAN 三大生成模型思想,标志着 TTS 技术从模块拼接走向结构统一。虽然VITS端到端,它仍然是连续潜变量。在VITS基础上,StyleTTS, NaturalSpeech改进其部件,加入了扩散模型,风格建模,多模态。
而以微软亚洲研究院 VALL-E(2023年1月)为代表的新一代TTS系统,引入了离散声学码(Discrete Acoustic Tokens)的概念。把语音当作语言来处理。从它开始,我们发现TTS进入了一个新的“范式转变”,我们不再关心“如何发出声音”,而是开始考虑“怎么说话”。
Vall-E通过神经编解码器,将音频压缩成离散的token序列,每个token大约数十毫秒,它不仅编码音色,还综合了局部的节奏、音高、能量特性。这种离散化方法,使得TTS系统像语言模型(GPT)一样操作声音序列:
- 支持局部编辑(editing)
- 支持风格迁移(style transfer)
- 支持局部修复(inpainting)
- 保持韵律自然流畅
2023年4月面世的Bark也是基于相同的架构,但进一步扩展到多模态音频生成。suno.ai利用扩散模型,实现了统一音频生成,文本,音效,音乐统一建模。它甚至emoji、停顿标点、语气词、描述性词汇,相当于音频GPT,而且可以运行在消费级GPU上。
2023年5月面世的XTTS是coqui.ai 开源的模型,它支持多语言,又引入了Prompt Token,可以实现多发言者的语言迁移。这个名字源于它的核心能力:用一段语言说话的样本,就可以用任意语言生成同样声音的人说话。技术上说,从参考音频提取说话人特征,注入到生成模型里。离散声学码的训练相当于大语言模型,成本高昂,创业公司难以与大公司竞争AI资源。
2024年的亚马逊模型Base TTS通过扩大参数规模,在性能上达到了一个新的高度。
离散声学码基本上遵循AudioLM结构,语音和声学Token单独训练,拼接生成。它的训练相当于大语言模型,成本高昂,创业公司的模型虽然设计精巧,屡有创新,但是它们往往不过数千万到数亿参数,更大的模型训练起来就太贵,大公司如微软,亚马逊,就可以凭借自身的AI显卡资源,成功训练十亿以上规模参数的模型,以算力霸榜。
最近的半年以来又出现两个新趋势:
统一语义和声学的Token
复旦大学的 SpeechTokenizer 论文建立了统一处理声学和语义的Tokenizer,这将前沿研究推进了一步。以前的离散声学码比如EnCodec,音色很好,但是不理解语义。HuBERT理解语义,但是音色较差。SpeechTokenizer把语义Token蒸馏进声学Token,在一个统一的Token里同时表达水平可以接受的语音和语义,则可以统一处理,不仅语义自然,节奏合理,而且音色真实,可以迁移。
流媒体式Token模型以Alibaba的CozyVoice2 和 Kyutai的Moshi为代表
CozyVoice2 实现 text + speech token 的交错建模,支持流式与非流式的统一语言建模,使模型可边听边说、随时调整回复。
Moshi 则是第一个端到端的语音到语音对话系统,彻底取消 ASR + NLP + TTS 的模块化流程,它实现 Inner Monologue 概念:模型在发声前内部先进行“内心语音推理”,建模了人类式“被打断-暂停-续说”的能力。
通过这种 token 流(token stream)的组织方式,模型不再是“句子-输出”机器,而是具备 动态节奏感与连续互动能力的语音交互体,如同一个会思考的说话人。
未来的TTS系统将不仅局限于语音合成,而是逐步走向全音频生成和多模态统一建模,融入动态粒度控制(Dynamic Granularity Editing)、零样本风格迁移(Zero-Shot Style Transfer)等前沿技术,进一步实现更真实、更个性化的人机交互。
语音识别:ASR
语音识别Audio Speech Recognition (ASR)同样经过了一系列的技术演进。ASR有独特的挑战,它要把连续的语音信号里离散化,找出有意义的实体,将其转变为文字。而语音信号里,每一个音素的发音并不是一成不变。同音词又如何选择合适的词?多人同时发声如何分离?对这些挑战的回应造就了今天的语音识别系统。
自动语音识别最早由 Bell Labs 在 1952 年实现的单说话人数字识别器开启。当时的系统仅能识别 0–9 十个数字,使用模拟电路和简单能量分析。尽管精度很高,错误率仅2%,但只能用于非常受限的任务。
1970年代早期,IBM 的 Jelinek 与 CMU 的 Baker 几乎同时独立地将隐马尔可夫模型(HMM)引入语音识别。这一创新提供了第一个能够严谨建模语音时序变化的统计方法。HMM 将语音看作一个状态序列,其中每个状态会生成某种概率分布下的声学观测。我们要做的,就是从可观测值,推算隐藏值的概率。
1980年代,美国国防部高级研究所资助了大规模语音识别研究项目,促成了 TIMIT、WSJ 等语音语料库的建立。同时,高斯混合模型(GMM)被用于建模 HMM 中每个状态的发射概率,通过多个高斯分布的叠加,可以模拟多样化的分布。识别系统结构由:特征提取 MFCC + HMM-GMM 解码器组成。
1990年代,随着计算能力提升和算法成熟,语音识别逐渐从“孤立词识别”走向“连续语音识别”,并支持更大的词汇表(1万~6万词)。同时,研究者发展了早期的语言模型n-gram来辅助词预测。n-gram计算常见词汇同时出现的概率,在声音相近的同义词中用来选择最合适的那个。对人类听觉感知的研究导致MFCC 作为主流声学特征广泛使用,它所使用的倒谱符合人体听觉对人类发声器官的识别规律,它保留共同的发音,去除个人的音色。这两种技术称霸排行榜很多年。接下来的十余年,系统性能趋于饱和。
2011 年起,基于深度神经网络(DNN)的声学模型首次大规模被用于语音识别,它可以很好的拟合各种分布,取代了 GMM 成为主流。早期的结构为 DNN-HMM 混合模型:使用 DNN 来估计 HMM 状态的后验概率 ,通过贝叶斯定理转化为发射概率。这一时期的成果显著提升了 ASR 性能,尤其是在嘈杂环境和非理想发音条件下。
2014年起,为了更好地处理长时依赖,循环神经网络(RNN)和 长短期记忆(LSTM)网络被引入语音识别。与此同时,CTC(Connectionist Temporal Classification)允许网络在无帧对齐标签下进行训练,催生了端到端(End-to-End)语音识别范式。它自动合并相邻的重复采样帧,因此,我们不再需要由模型明确的判断每一个音的开头和结尾时间。当然,带来的问题是,重复字符发音也一起被合并。
其中,Google Deep Speech 采用 RNN-CTC 架构,首次提出不再依赖 HMM 的识别系统。
2017–2020:Attention 与 Transformer 模型
随着注意力机制的发展,基于 Transformer 的模型,如 Listen, Attend and Spell(LAS),Conformer,逐渐成为主流。它们提供了更强的建模能力,支持并行计算,也适合长距离上下文建模。端到端模型逐步成熟,结构包括:
- CTC(无需对齐)
- RNN-T(在线识别)
- Encoder-Decoder(如 LAS)
- Transformer / Conformer(注意力机制)
这些模型常常集成语言模型、发音词典等组件,超越了传统系统的表现。
2021–至今:大模型与预训练
现代语音识别系统正与大型语言模型融合,如:
- Whisper(OpenAI):使用大规模数据训练的多语种、多任务语音识别模型
- wav2vec 2.0(Meta AI):利用自监督学习在大量未标注音频上进行预训练,再微调完成语音识别任务
- SpeechLM、HuBERT、Data2vec 等多模态语音语言模型
这些方法使 ASR 系统无需从头训练,能够更好地适应低资源语言与复杂环境。这些先进方法包括:为空白建模,无声也是一个因素。在语音Token之上训练出语义识别。
ASR的总体技术发展趋势是:特征工程 → 概率建模 → 神经建模 → 数据驱动预训练
这些语音识别的训练方式,越来越接近人类婴儿的语音学习方式。
语音学的未来
尽管现代深度学习系统能够自动从语音数据中学习字音映射、语调模式,甚至跨语言迁移特征,但当模型出现偏差或识别失败时,问题常常回到最基础的问题:模型是否理解了语言背后的语音机制?
在这方面,语音学提供了两种重要支持:
- 诊断工具:帮助工程师判断语音系统在哪个环节出现问题;
- 设计参考:为模型架构、特征设计与数据增强提供语言层级的视角。
语音学并非被深度学习取代的旧知识,而是在智能系统中以另一种形式延续并重构的框架。它不仅解释人类如何发声,也启发我们设计能「听懂」、「说出」甚至「模仿人类语调」的智能系统。
另一方面,现在的计算机语音研究越来越多地涉及:
- 深度学习 (Deep Learning)
- 自监督学习 (Self-supervised Learning)
- 大语言模型 (Large Language Models)
- 多模态建模 (Multimodal Modeling)
这些技术领域使用了语音学的术语(如音素、韵律),但已经不再主要关注语音本身的基础机理、声学与感知,而是关注于模型训练、数据驱动与神经网络结构优化。因此可以说:当前的TTS和ASR已经明显超出了传统语音学范畴,变成了一个高度跨学科的领域,包含语音学、语言学、深度学习、信号处理、机器学习、NLP 等众多交叉领域。TTS和ASR不仅限于语音学本身。
而语音学成为基础知识,将在未来人与机器共同演化的过程中,持续提供其独特而不可替代的洞见。