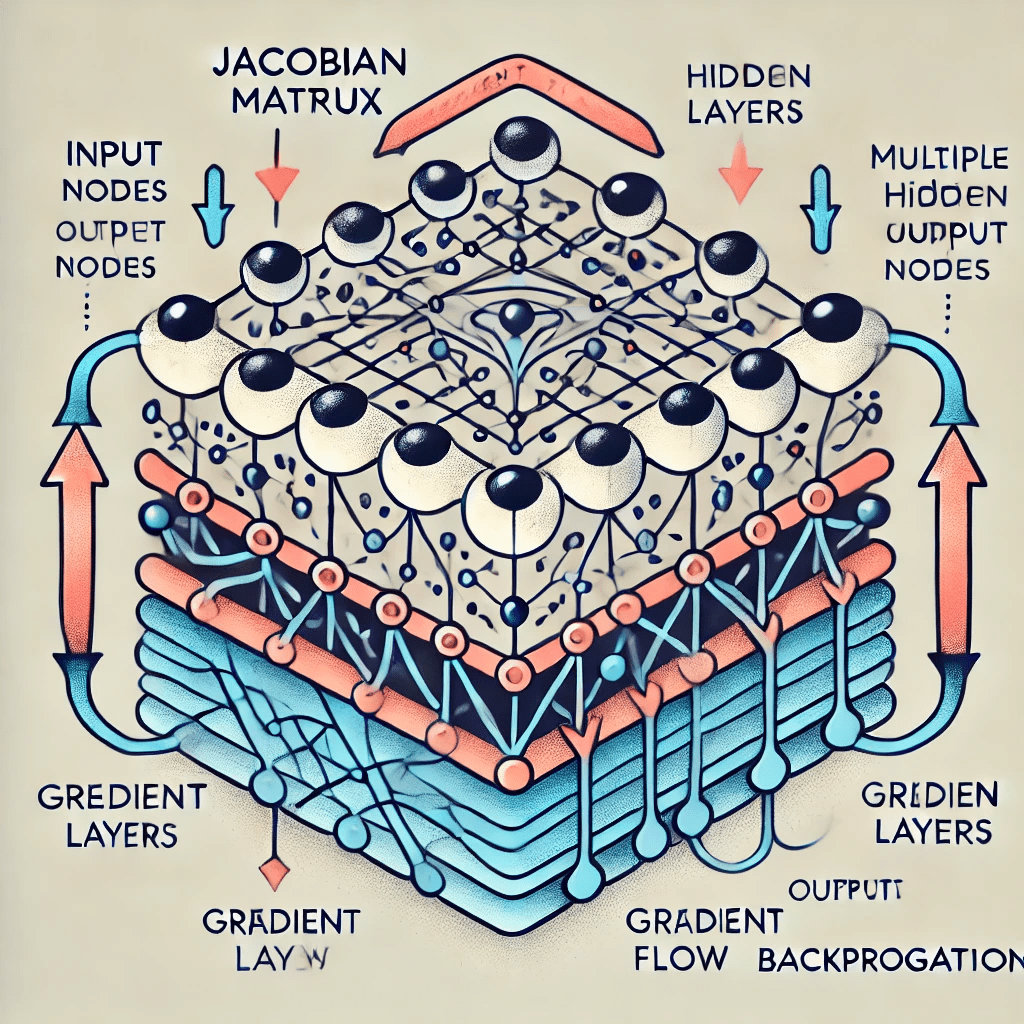
当前的自然语言处理依赖基于深度学习训练出来的神经网络模型,它通常是一个多输入、多输出的复杂函数。模型结构多种多样,基本的前馈神经网络就是输入层->隐藏层->输出层。他构成了神经网络的基础。更加复杂的RNN模型有循环结构,CNN模型有卷积层,Transformer模型有自注意力。
神经网络的多层结构存储了权重,偏置,激活函数等等。内在数据和输入进行运算后会得出一系列的输出值,我们比较输出值和实际数值(我们希望模型产生的数值)偏差有多大,然后我们根据偏差的方向,更新模型的权重来让这个输出值更加接近实际值,经过多次反复训练之后,模型的输出非常接近实际值,就算训练完成了。
在数学上,我们需要计算每个输入对每个输出的影响到底有多大,然后更新模型的权重,我们通常使用雅可比矩阵 (Jacobian Matrix)来表达多变量函数的偏导数矩阵。它本质上就是一个“变化率表”。描述了一个多变量函数的输出如何随着输入的变化而变化。在深度学习中,雅可比矩阵被广泛用于梯度计算和反向传播 (Backpropagation),帮助模型不断学习并优化参数。
一个简单的例子,假设你是一家咖啡店的老板,你的店里有三种原料:
- 咖啡豆x 1
- 牛奶x2
- 糖x3
你售卖两种饮品:
- 美式咖啡y1 – 只用咖啡豆
- 拿铁y2 – 用咖啡豆、牛奶和少量糖
可以用数学公式表示:
- 美式咖啡:
y1 = 2 x1 - 拿铁:
y2 = x1 + 3 x2 + 0.5 x3
雅可比矩阵表示的是:每种原料 (输入) 增加 1 单位,对饮品数量 (输出) 的影响。
公式为:

解读:
- 第一行:美式咖啡 y1 的变化率,咖啡豆每增加 1 单位,y1 增加 2,牛奶和糖对美式咖啡没影响,所以导数是 0
- 第二行:拿铁 y2 的变化率,咖啡豆每增加 1 单位,y2 增加 1,牛奶每增加 1 单位,y2 增加 3,糖每增加 1 单位,y2 增加 0.5
这个雅可比矩阵描述了输入 (原料) 如何影响输出 (饮品)。在深度学习中,神经网络通过反向传播 (Backpropagation) 来计算梯度,从而更新参数。
为了完成自然语言处理(NLP)任务,我们在这个简单的例子的基础上增加一些其它的计算,比如在命名实体识别(NER)中,我们希望分析下面这句话:
Museums in Paris are amazing
我们在关注当前词 Paris 的时候,我们希望知道,在当前语境当中,Paris到底是指什么,是那位出名的美女富豪,法国首都,还是特洛伊王子?那么我们需要知道,附近的哪些单词对于确定当前单词的意义更加重要。因此,我们可以给所有的单词赋予一个权重。然后测算,给哪些词赋予更高的权重,能够得出更准确的结果。所以,我们添加一个权重向量 u,转置之后与模型权重和偏置之后的输出相乘。很明显,第一个词 Museums 是一个关键词,看到这个词,我们就知道Paris指得是法国首都,其中u0代表了第一个词,因此它最重要,应该占最大的概率。所以针对权重向量u我们做一个归一化计算softmax,全部元素加起来等于1,这就可以把它看作一个概率。最终如果我们成功的训练了网络,假设u0大约是0.95,其它的加起来占0.05,基本上就成功了。
在这个时候,每一层神经网络的计算可以表示为:
- z = W x + b
- h = f(z)
- s = u^T h
其中:
- W 是权重
- b 是偏置
- f(z) 是激活函数(例如 ReLU 或 Sigmoid)
- u^T 是最终输出的单词重要度加权求和
雅可比矩阵的作用:
- 梯度计算:雅可比矩阵帮助我们计算梯度,进而更新权重 W 和偏置 b 。
- 反向传播:在反向传播过程中,雅可比矩阵用来逐层计算梯度,从输出层往输入层传递。
假设一个神经元计算如下:
- z = 2 x + 3
- h = ReLU(z) = max(0, z)
如果 x = 1 ,那么:
- z = 2 x 1 + 3 = 5
- h = max(0, 5) = 5
如果 x 增加到 1.1:
- z = 2 x 1.1 + 3 = 5.2
- h = 5.2
可以计算得到:

这个 2 就是雅可比矩阵中的导数,表示 x 每增加 1,h 就增加 2。
在深度学习中我们按照这个示意图进行计算

黑色文字表示前向传播 (Forward Propagation):从输入层开始,一层层计算输出,直到最终输出层。
蓝色文字表示反向传播(Back Propagation),从输出层开始,利用雅可比矩阵,层层计算梯度。更新每一层的参数(权重和偏置)。
针对每一个节点,看上去就是这样。

把向量和矩阵分解成元素来看,它和人类神经元对比有相似之处。神经元通过树突和轴突收发信息,相当于函数的输入和输出。其突触强度表示神经元彼此影响的重要性,相当于权重。如果最终的信号总和超过某个阈值,该神经元就会发射信号,沿着轴突发出一个尖峰。但是神经元数量极多,类型繁多,信号承载数据的方式极其复杂,现在的计算机无法产生接近人类神经元的网络。
不过产生高等智力,并不需完全模拟人类。飞机的发明并不需要学习鸟类扑翼。早期的扑翼机试验无一例外全都失败了,只有固定翼飞机取得了成功。
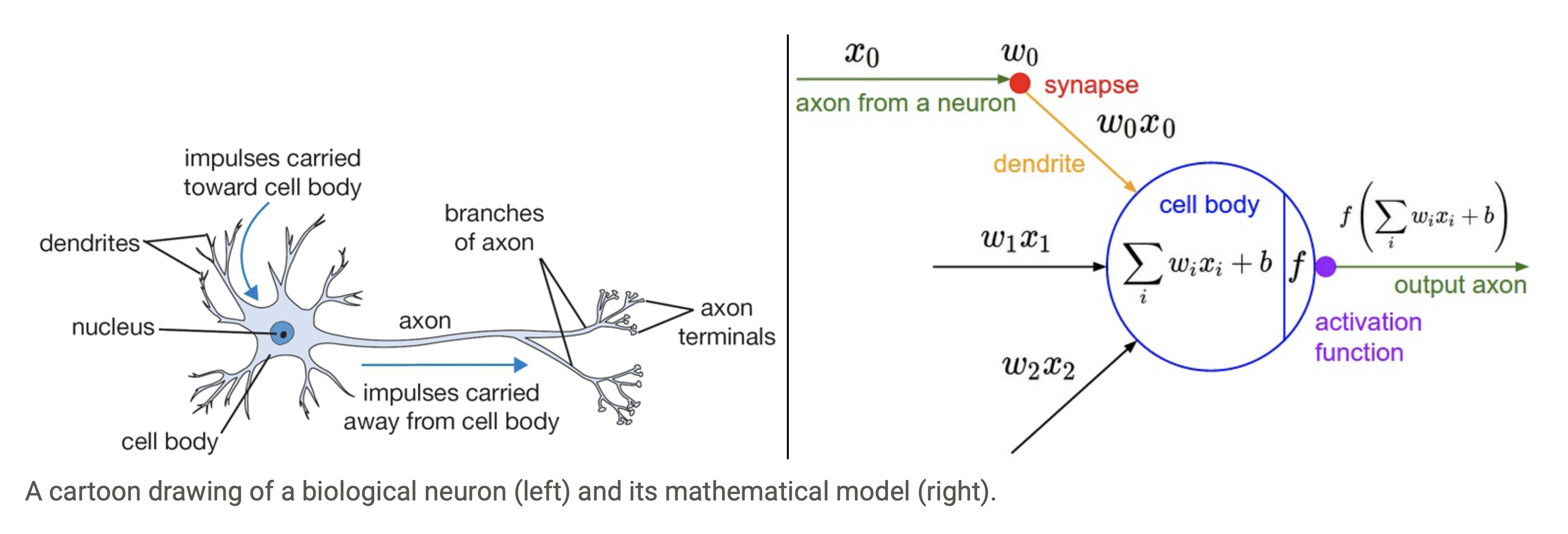
单个人类神经元或者单层计算机神经网络只能做出线性决策,这相当于只会画直线。多层神经网络包含非线性激活函数,可以做出复杂决策。神经网络的梯度计算公式:
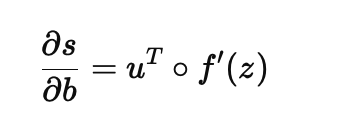
- f'(z) 是激活函数的导数
- u^T 是输出层的权重
- 圆圈运算符 ⭕️ 是逐元素相乘(Hadamard Product)
这个公式表示:
- 偏置 b 如何影响最终输出 s 。
- 雅可比矩阵 用来计算这个梯度,指导梯度下降更新 b 。
在深度学习模型中,我们用计算图Computational Graph 来计算和储存每一步的偏导数。这些偏导数通过链式法则分解来计算,未来再相乘得到新的梯度,每次计算的时候,被分解的偏导数大部分可以重新使用,只需要计算一个较小的变化部分。
在前向传播时,计算图会存储每一层的中间值(例如 z 和 h),这些值在反向传播中用于计算梯度。反向传播时,雅可比矩阵中的梯度逐层相乘并传递,每一层的梯度会被缓存 (Cache),以便后续计算重用。
深度学习框架(如 TensorFlow 和 PyTorch)使用自动微分(Autograd) 来计算雅可比矩阵和梯度。相应的,自动微分具有两种模式:
- 前向模式 (Forward Mode):从输入到输出计算导数,不适合深度网络。
- 反向模式 (Reverse Mode):从输出反向计算梯度,是深度学习中广泛使用的方式。
其中,早期版本的TensorFlow仅使用静态计算图 (Static Graph)。先定义计算图,再启动Session执行。在编译图时确定依赖关系,并且在反向传播时按需计算梯度并缓存。
PyTorch: 使用动态图 (Dynamic Graph)。每一行都会立即计算并且返回结果,然后可以调整再计算,每次前向传播都会重新构建计算图,梯度保存在 .grad 属性中。
静态计算图编译时优化当然比较高效,但是不灵活,不容易在开发的时候进行探索和尝试,也不容易调试。这相当于编译型语言和解释型语言的区别,也间接导致了TensorFlow在研究人员群体内的流行程度不如Pytorch。现在的主流全是使用PyTorch。

发表评论